
界面新闻记者 |
界面新闻编辑 | 刘方远
界面新闻获悉,在第五届字节跳动奖学金颁奖典礼上,字节跳动技术副总裁杨震原分享了字节跳动自2014年以来在技术领域的一些探索历程。
杨震原表示自己是一个技术爱好者,2014年加入字节跳动之后,从最初负责搭建新的推荐系统开始,到现在已经有快12年了,他也一路参与了字节很多的技术探索。
多数人对字节跳动的了解集中在抖音、今日头条、TikTok等产品上,但杨震原分享了诸多外界不熟悉的技术探索。
以下为界面新闻整理的分享要点:
2014年:第一版机器学习与推荐系统就定了一个非常激进的目标

2014年,工业界最大规模的机器学习系统,是搜索广告中已经成熟使用的大规模离散LR(Logistic regression)。把这套原理用在推荐系统上,挑战可不小。那时同时熟悉大规模软硬件工程和机器学习的人不多,而且,除了能够挣到很多钱的搜索广告会使用;其他领域,大家都不愿意花这么大的硬件成本去做计算。
我们第一版就定了一个非常激进的目标:计划2014年做到万亿(T)级别的特征规模。这里有非常多的挑战,比如系统建模,处理好推荐的优化目标。工程上,存储和计算是最前期的门槛。另外我们也要做好算法的优化。
14年底,我们逐渐引入了FM类算法,后来演化成了更通用的deep learning体系。而且从我们上线的第一天,它就是一个streaming training的系统。
到今天,我们发现streaming更新(training only)的、较浅层的神经网络算法在推荐中依然有着不错的效果。它可能和现在 test-time training中的一些问题相关,也许是更近似RNN的一个实现。
2020年:科学计算的探索
大概 2019 年底到 2020 年,我们讨论过一次,未来AI还能够怎么发展,如何在全社会发挥更加重要的价值?
当时的思考是,只有很大规模的有价值的数据,才能够产生足够有价值的模型和算法。线上世界,推荐、搜索、广告是主流应用。那么,还有什么场景能够产生很多有价值的数据呢?显而易见是现实世界。但现实世界的数据搜集与应用会比较复杂,涉及到无人车、机器人等领域。除了现实世界,我们还想到一点,那就是科学计算。
从2020年开始,我们在第一性原理计算上持续投入。这个领域早期代表性的工作是DeepMind的FermiNet等,2019 年我们几个人在会议室里就讨论过这项工作。这个领域叫做NNQMC(神经网络量子蒙特卡洛方法)。 QMC 是量子蒙特卡洛,根据变分原理,任何试验波函数 计算得到的系统能量 总是大于或等于真实基态能量。于是,我们就可以用神经网络去表示一个波函数,然后,在这个波函数上进行采样并计算系统能量。然后,我们就可以按照能量更小方向的梯度去更新神经网络,最终得到一个更优的波函数表示。
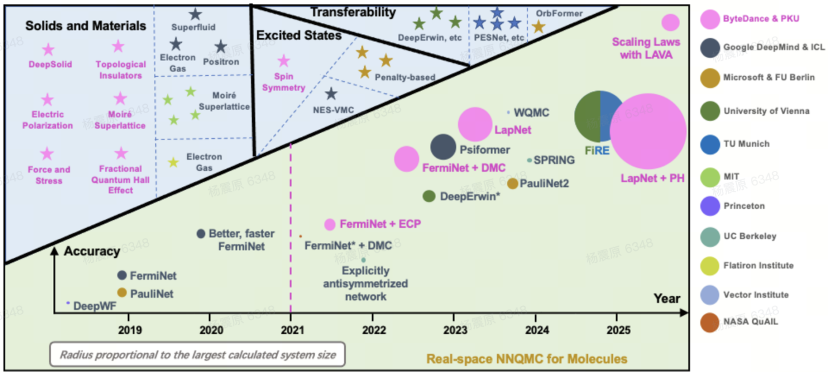
粉色部分是我们在 2021 年之后的几项工作,我们基本上在业界已经做到前沿。这张图的纵坐标指的是仿真精度,就是与物理实验的接近程度。仿真越接近真实,应用前景就越好。圆的大小表明了仿真体系电子的数量,这个圆越大,也就意味着它有更大的实用价值。最右上角有一个Scaling Laws with LAVA,这是我们最新的一个成果。我们发现,这个问题和大模型一样表现出Scaling Law,如果我们使用更多参数,就会看到它的仿真精度是持续上升的。这是一个很好的信号,说明我们可能在实用性方面还有很大的突破潜力。
我们在分子动力学上也有很多探索。我们的思路是,先改进正问题。使用更高精度的仿真来给机器学习MD的力场提供更精准的label。DFT(密度泛函分析),是一个合理的层次。我们首先做了DFT的GPU加速工作。我们的GPU4PySCF,实现了GPU加速DFT计算的业界SOTA。相比传统CPU计算程序,实现速度1GPU≈500~1000CPU core的加速,完成相同计算任务算力成本降低1个数量级。
我们的团队开发了Bamboo-MLFF和ByteFF两类分子动力学力场,对分子、固体体系的性质进行准确预测。其中ByteFF-Pol目前在无实验数据zeroshot预测电解液性质上实现了业界SOTA的精度。这些工作不仅仅只在我们的实验里。我们今年已经和BYD成立了联合实验室,会将高通量自动化实验与科学计算算法结合,探索AI for Science在电池材料领域的工业落地应用。
2021年:XR的探索,更多投资基础技术
XR是有潜力能带来全新的体验。2021年,字节收购了Pico团队。
收购后,我们有两个产品路线在同时推进。一个是,以当前的产品形态为主,同时投入资源运营视频、直播等内容,较为激进的营销。路线二,是投资基础技术,追求核心体验上一个大台阶。
2023年,我们决定减少内容和营销投入,更坚定的投入技术路线。这是因为当时产品的硬件体验尚未成熟,无法支撑大规模市场应用。这个调整当时还带来了一些误解,不少人说字节不做这个方向了。其实恰恰相反,23年开始,我们在XR上的技术投入比以前更多。
在技术上中,我们一方面在清晰度上进行了探索。XR要模拟人眼观察真实世界的体验,关键指标是PPD(每度像素数),就是说人眼睛看一个度(degree),大概有多少像素。
2022年我们开始研究怎么能做好,最后决定和供应商启动MicroOLED定制。MicroOLED是一种在单晶硅片上制备主动发光型OLED器件的新型显示技术。
相比于其他显示技术(如高 PPI 的 LCD 液晶屏),microOLED 在实现单眼 4K 等级的超高分辨率时,仍然能够保持更小的面板尺寸。这使得光学显示系统得以进一步缩小,从而让 MR 头显轻便的同时获得更高的 PPI 和整体清晰度。我们通过导入微透镜(MLA)来提升亮度,副作用是色亮度均一性变差。这就需要,结合光学设计,通过主光线角(CRA)定制和系统性补偿上的一些工作,让亮度和色亮度均一性同时达到最优状态。

另一方面,MR 也是重要的技术挑战。如果这方面做得不好,就会让人产生眩晕感。如何低延迟、高精度的完成这个计算,就是核心问题。
2022年6月我们正式立项,全链路自研了一颗头显专用的消费电子芯片来解决这个处理瓶颈。芯片在2024年回片,目前进入量产阶段,各项指标均达到设计要求。
目前在实测中,我们的系统延迟可以做到12毫秒左右,这是非常不容易的。即便是世界顶尖的公司,用软件来做的话,也很难在不明显牺牲画质的前提下把延迟压到25毫秒以内。
同时,交互的挑战也非常重要。我们如果希望做虚实融合,那需要对现实环境做识别。我们需要非常高精度的ground truth进行校准与训练。为此,我们建设了专业的高精度测试系统。
2023年:大模型的时代
2022 年11 月30 日,ChatGPT横空出世,2023年引起广泛关注。我们在2021年,有过一次机会早点关注到。
2022年,我们在这个方向上开始投入。现在,我们也取得了一些成果。应用上大家可能更熟悉一些,豆包是中国最流行的AI对话助手,火山引擎的大模型服务也受到客户的认可,根据IDC的报告,火山是中国MaaS市场的第一名。
技术上我们也有自己的特点。得益之前的一些积累,我们在Infra方面做的还是比较好的。我们很早就建设了大规模的稳定训练系统MegaSacle,在训练任务上,MFU(浮点运算利用率)超过55% ,这是当时主流开源框架的1.3倍以上,效果还是很不错的,有兴趣的可以去看我们24年年初发的相关论文。
我们在模型结构、自研服务器上也有很多探索,这也让我们实现了大模型的低调用成本。所以,我们在通过火山引擎提供服务的时候,才能够打破业界价格下限,同时保证自己有不错的毛利。
AI的能力发展是非常不均衡的,今天大模型可以在国际数学奥林匹克上拿到金牌,这恐怕已经超过了99.9%的人类。但对于很多工作,比如,一个初中生可以胜任的电话客服工作,大模型目前还不能完全做好。
为什么会这样?一个比较直观的,是模型的学习能力。目前的大模型是分阶段的,训练阶段和推理阶段。当模型部署到线上开始服务,就不再被训练,或者说,只能做in context learning。这和人类是不一样的。人类是持续在学习的。
比如电话客服,一个名校的博士可能刚开始也不知道怎么做好,但人可以很快学习,可能用不了几天就可以把工作做好了。而且人的学习效率很高,并且充分利用社会环境,比如他可以问一下老员工或者经理该怎么做。
所以说,如何让大模型提高学习能力,是一个比较重要的问题。最好是每一个人都可以以他的方式教知识给大模型。
第二个能力是IO能力,也就是和这个世界交互的能力。这个也显而易见。即便在数字世界,虽然目前的大模型,在视频、图片合成方面的能力已经超过人类,但是在众多内容理解、界面操作等方面,模型还是和人有比较大的距离。这些都是非常基础,但非常值得研究的问题。
有人说,2023年是人类历史上的第3个奇迹年,我觉得丝毫不为过。AI的发展给人类社会预期会带来巨大的变革,这场变革里会有无数的问题,需要技术人去探索,去解决。字节跳动也会在大模型等前沿领域,持续耐心的探索下去,希望能够为人类社会贡献自己的力量。




还没有评论,来说两句吧...